Well, it’s not an entire lecture, not even quite half a lecture. But my favorite part of a lecture in college algebra is the properties of exponentiation. Sounds strange, right? I basically list off some algebraic identities involving exponents, and I’m done. The value does not lie in the content, but in the presentation of the material, and how it comes the closest to what I enjoy about math.
We start with  and
and  natural numbers. We notice that when looking at
natural numbers. We notice that when looking at 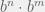 , this is first multiplying
, this is first multiplying  a total of
a total of  times, and then multiplying another
times, and then multiplying another  times. So this is the same as multiplying a total of
times. So this is the same as multiplying a total of  times, or
times, or  Here I might take a specific like
Here I might take a specific like  and
and  and write it out. So we get the equation
and write it out. So we get the equation  .
.
Next if we take a look at 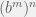 , we can expand it out as multiplying
, we can expand it out as multiplying  a total of times. So
a total of times. So  , then being a little suggestive, I expand the out vertically, creating an array of ‘s. Then it becomes clear by appealing to the area of a rectangle that this quantity is
, then being a little suggestive, I expand the out vertically, creating an array of ‘s. Then it becomes clear by appealing to the area of a rectangle that this quantity is  the result of multiplying a total of
the result of multiplying a total of  times.
times.
So here’s the part I love. So far, we have appealed to the nature of exponents as repeated multiplication to deduce some properties about it. I then say that these are nice algebraic properties that will make our lives easier when we have to deal with exponentials, wouldn’t it be nice if they were still true even after we consider more general ? So let’s pretend they do still hold and see what happens.
We first take a look at 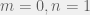 and by looking at the addition property we get that
and by looking at the addition property we get that  , and since
, and since  and
and  , we see that
, we see that  , and if we divide both sides by , we see that
, and if we divide both sides by , we see that  . So we get a very specific value for . It wasn’t something handed down from the heavens, it wasn’t some convoluted aspect of
. So we get a very specific value for . It wasn’t something handed down from the heavens, it wasn’t some convoluted aspect of  , or strange combinatorics. Just we want this addition property to be true, and for it to be so,
, or strange combinatorics. Just we want this addition property to be true, and for it to be so, 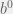 must be
must be  .
.
Then we take a look at negative numbers. So we let be any positive whole number and use the addition property and notice that 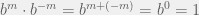 . So erasing the middlemen, we have
. So erasing the middlemen, we have 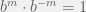 , or by dividing both sides by
, or by dividing both sides by  , we have
, we have  . Now we have that negative exponents correspond to the reciprocals. Again something that pops out, just because we wanted to keep that addition property.
. Now we have that negative exponents correspond to the reciprocals. Again something that pops out, just because we wanted to keep that addition property.
Finally we look at rational numbers. We first we deal with  . Finally the other property comes into play:
. Finally the other property comes into play:  . Cutting out the middlemen again, we see that
. Cutting out the middlemen again, we see that 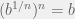 . But there is a special name for a number whose th power is equal to (when
. But there is a special name for a number whose th power is equal to (when  , and that is the th root of , written
, and that is the th root of , written ![\sqrt[n]{b}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bn%5D%7Bb%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) . As for the arbitrary case, we see that since
. As for the arbitrary case, we see that since  , and so
, and so ![b^{m/n}=(b^{m})^{1/n}=\sqrt[n]{b^m}](https://s0.wp.com/latex.php?latex=b%5E%7Bm%2Fn%7D%3D%28b%5E%7Bm%7D%29%5E%7B1%2Fn%7D%3D%5Csqrt%5Bn%5D%7Bb%5Em%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.
Now, I may not have persuaded you that this is a good lecture, let alone one deserving of being called a favorite. The first thing to notice is that there are few hard quantities involved; it’s mostly algebra. When these classes are taught, the first thing a (pure) mathematician notices is that it’s deprived of any interesting abstract mathematical ideas. The teacher is forbidden (for good reason!) from straying too far into his own domain of general theory, and focus on the particular, lest the students become confused and bewildered. The more headstrong mathematician-teacher charges ahead anyway, and is met with sighing, head scratching and yawning. Proving the quadratic formula by completing the square of an arbitrary quadratic functions sounds like a great idea, but it’s a quick way to lose a room full of freshmen. This has a wonderful balance; easy enough that the algebra clarifies rather than obfuscate, yet complicated enough, that it says something actually interesting and not at first obvious.
Also take note that the progression of our ideas follows the same construction of the rationals from the natural numbers. We starting with a counting device; consider repeated counting, also called addition and then repeated addition, which we call multiplication. We consider 0 the neutral element in addition. Then we follow-up with negative numbers, or in more algebraic terms, the additive inverses we get from extending our monoid of natural numbers to the group of integers, which turns out to be a ring. We then form the ring of fractions, which give us multiplicative inverses. We follow the same chain of constructions without mentioning the fact that we are doing so, so we implicitly form a picture of the way numbers work without having to explicitly talk about a great deal of abstract algebra.
But what seems like the most important thing I love about this is the premise of the lecture. We begin with an observation that exponents work in a certain way, when we consider natural numbers. In particular, it’s very natural, almost completely obvious. Now rather than making rules for the other numbers and noticing that we get the same properties, making them more complicated by having so many cases, we say “wouldn’t it be nice if this still held?” And the point isn’t “This is how things are,” but “we want this, and we accept the consequences of our choice.” Too often, math is considered a bunch of strict rules, like a code of law. “You are allowed this action, but not this one.” And I admit I encourage this view, especially when dealing with things like dividing fractions, or adding fractions or… pretty much anything involving fractions. But this isn’t how math is, not the kind I love so much. It allows for so much creativity and invention. The only truly mathematical law is “Be consistent,” which is admittedly more restrictive than at first appears. But we allow every twist and turn of every possible mathematical rule or system and allow a complete freedom provided one thing: we must accept the logical consequences of our choices. “Everything not forbidden is permitted.”
be a C*-algebra and let
is approximately diagonalizable if for every
, there exist elements
and a unitary
such that
.
be a compact metrizable space. Every self-adjoint matrix in
is approximately diagonalizable if and only if
and
.
.



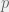

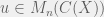




.
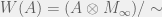

.

 of being heads and probability
of being heads and probability  of being tails, and play a familiar game: flip the coin until it lands on tails. The possibilities are exhausted as follows: tails first; heads then tails; two heads then tails; three heads then tails; etc, and always heads forever. The last option has probability zero (not to be confused with impossible) because the probability of that option is less than the probability of getting
of being tails, and play a familiar game: flip the coin until it lands on tails. The possibilities are exhausted as follows: tails first; heads then tails; two heads then tails; three heads then tails; etc, and always heads forever. The last option has probability zero (not to be confused with impossible) because the probability of that option is less than the probability of getting  which converges to 0 as
which converges to 0 as  , so since the probability of always getting heads is less than all these it must be 0.
, so since the probability of always getting heads is less than all these it must be 0. . So we have that
. So we have that  , or if we divide by
, or if we divide by  , we get:
, we get:  .
.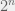 dollars, where
dollars, where  .* So the expected value here is infinite! Okay, so that means we should spend any amount of money on this game, because no matter what it’s a good deal.
.* So the expected value here is infinite! Okay, so that means we should spend any amount of money on this game, because no matter what it’s a good deal. tails and then heads. So the probability of getting that specific combination is
tails and then heads. So the probability of getting that specific combination is  .
.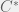 -algebra is without knowing the context for why it is what it is. When trying to motivate mathematics, it seems as though the best option is to look at why they were first studied. So I will begin not quite at the very beginning, but an important historical result and for that I need to first talk about topology.
-algebra is without knowing the context for why it is what it is. When trying to motivate mathematics, it seems as though the best option is to look at why they were first studied. So I will begin not quite at the very beginning, but an important historical result and for that I need to first talk about topology.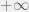 or
or  to denote that it is not bounded on whichever side. One of the problems with this is that now it seems as though we’re treating “infinity” as though it’s a number. People have some conceptual notion of infinity prior to any formal knowledge of how mathematicians use the idea Childhood number topping games trumped by crying out “Infinity,” only to be refuted with a “Infinity + 1” come to mind. Encouraging it seems like a bad idea as if one every gets to talking about when such concerns about infinite sets or real numbers arise the naive notion inclusion of infinity as a number. The usual way of explaining it away is the unsatisfying answer that “Infinity is a concept, not a number.” But that’s strange, what makes something a “concept” and what for that matter is a “number”?
to denote that it is not bounded on whichever side. One of the problems with this is that now it seems as though we’re treating “infinity” as though it’s a number. People have some conceptual notion of infinity prior to any formal knowledge of how mathematicians use the idea Childhood number topping games trumped by crying out “Infinity,” only to be refuted with a “Infinity + 1” come to mind. Encouraging it seems like a bad idea as if one every gets to talking about when such concerns about infinite sets or real numbers arise the naive notion inclusion of infinity as a number. The usual way of explaining it away is the unsatisfying answer that “Infinity is a concept, not a number.” But that’s strange, what makes something a “concept” and what for that matter is a “number”? as part of an “extended” real number line, or to say “Infinity is a concept, but not a number”? If the latter, what are we trying to say with that?
as part of an “extended” real number line, or to say “Infinity is a concept, but not a number”? If the latter, what are we trying to say with that? ?
? for
for 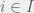 is summable, if there exists a vector
is summable, if there exists a vector  such that for all
such that for all 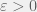 there exists a finite set
there exists a finite set  such that for any finite set
such that for any finite set  , we have
, we have  . We write
. We write  .
.
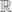 is a (real) Banach space and
is a (real) Banach space and 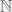 is a perfectly good indexing set. We get our usual definition of summation if we restrict our attention to
is a perfectly good indexing set. We get our usual definition of summation if we restrict our attention to 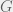 of the form
of the form  . This means that our definition of summation is more restrictive than our usual definition for sequences, but we notice that it is equivalent to having
. This means that our definition of summation is more restrictive than our usual definition for sequences, but we notice that it is equivalent to having  be convergent series for all permutations
be convergent series for all permutations  . Equivalently,
. Equivalently,  is summable (in our sense) if and only
is summable (in our sense) if and only  is absolute convergent. Considering the advantages of absolute convergence over convergence and the fact that absolute convergence makes little intuitive sense, it is tempting to consider this definition over our traditional one. Alas, there are too many practical difficulties with this definition to introduce in a calculus course.
is absolute convergent. Considering the advantages of absolute convergence over convergence and the fact that absolute convergence makes little intuitive sense, it is tempting to consider this definition over our traditional one. Alas, there are too many practical difficulties with this definition to introduce in a calculus course.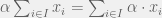 ,
,  , which passes from the fact that these are true when
, which passes from the fact that these are true when  is finite. (Though technically, one must show that the sums are unique.)
is finite. (Though technically, one must show that the sums are unique.) such that
such that  , we have
, we have  .
. one has
one has 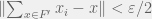 . Take a set
. Take a set  and consider
and consider  , we then have
, we then have  . So that proves one direction. Now suppose the Cauchy condition holds. Let
. So that proves one direction. Now suppose the Cauchy condition holds. Let  be a finite set such that if
be a finite set such that if  , then
, then  . By replacing
. By replacing  with
with  , we may assume that
, we may assume that 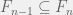 for all
for all  is countable and if
is countable and if  , then
, then  , then
, then  . So the sequence converges and we see that if we take any
. So the sequence converges and we see that if we take any 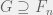 , then
, then  . The former converges to zero as
. The former converges to zero as  of independent, identically distributed random vectors in
of independent, identically distributed random vectors in  . These vectors correspond to the steps that our random walker (or flyer as the case may be) are taking. The example of interest to us is where we take the standard basis vectors and vectors obtained by multiplying them by -1 and give them uniform probability of being chosen. We will call this the simple random walk. So in the case of
. These vectors correspond to the steps that our random walker (or flyer as the case may be) are taking. The example of interest to us is where we take the standard basis vectors and vectors obtained by multiplying them by -1 and give them uniform probability of being chosen. We will call this the simple random walk. So in the case of  , we have a
, we have a  chance of going up, down, left or right. To keep track of the walker’s position, we just need to add up the vectors:
chance of going up, down, left or right. To keep track of the walker’s position, we just need to add up the vectors:  .
.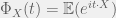 , and by independence we have
, and by independence we have  . This follows quickly from the fact that
. This follows quickly from the fact that 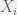 are independent and identically distributed. But we pause here briefly, to mention the fact that rare numerical equality of the integral of a product with the product of integrals is the very condition of independence, about which we usually rely on our intuitive notion. This quickly reminded me about Mark Kac’s monograph about the subject, but maybe more on that later this month.
are independent and identically distributed. But we pause here briefly, to mention the fact that rare numerical equality of the integral of a product with the product of integrals is the very condition of independence, about which we usually rely on our intuitive notion. This quickly reminded me about Mark Kac’s monograph about the subject, but maybe more on that later this month.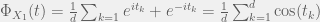 .
.![[-\pi,\pi]^d](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C%5Cpi%5D%5Ed&bg=f0f0f0&fg=555555&s=0&c=20201002) , we have that the functions
, we have that the functions  form an orthonormal basis for
form an orthonormal basis for  , and that by definition of expected value, one has
, and that by definition of expected value, one has 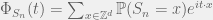 . So we have that our characteristic function can be written as a linear combination of our orthonormal basis, but more to the point, we have numerical values for the coefficients of that sum by taking inner products!
. So we have that our characteristic function can be written as a linear combination of our orthonormal basis, but more to the point, we have numerical values for the coefficients of that sum by taking inner products! , or to put this in integral terms:
, or to put this in integral terms: ![\int_{[-\pi,\pi]^d}\!\Phi_{X_1}^n(t)e^{-it\cdot x}\,dm=\mathbb{P}(S_n=x)](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B-%5Cpi%2C%5Cpi%5D%5Ed%7D%5C%21%5CPhi_%7BX_1%7D%5En%28t%29e%5E%7B-it%5Ccdot+x%7D%5C%2Cdm%3D%5Cmathbb%7BP%7D%28S_n%3Dx%29&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.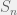 and the characteristic function, we have something that we can estimate and prove the theorem.
and the characteristic function, we have something that we can estimate and prove the theorem.